💡 easy guide to: Understanding Retrieval-Augmented Generation (RAG)

What is Retrieval-Augmented Generation (RAG), why does it stand out as an innovative framework? By integrating external knowledge, RAG enhances large language models (LLMs), allowing them to deliver more precise, current, and dependable responses. Together let us explore how RAG is transforming our interactions with AI.
Getting the Latest Information
Imagine asking a language model about today's weather in Paris. Without RAG, the model might base its answer on pre-existing, potentially outdated data, leading to inaccuracies. With RAG, however, the model can integrate the latest available information from reliable sources, enhancing the accuracy of its responses. The recency of this information depends on the specific implementation of RAG and the connected database.
The Need for RAG
Although large language models are powerful, they sometimes produce inconsistent or inaccurate results. They excel in recognizing word patterns but often miss deeper meanings. RAG addresses this by integrating additional information from sources outside the model’s initial training data, improving the quality of its responses. However, it’s important to note that the model can only be "grounded" with information that is included in the RAG pipeline.
The Benefits of RAG
Access to Current and Reliable Information:
RAG ensures models use the latest, most trustworthy information, enhancing response accuracy. Users can verify the sources, building trust in the system.
Enhanced Privacy and Data Security:
One of the major benefits of RAG is the ability to enhance LLM outputs with your private or internal data without needing to send this data externally for training. This reduces the risk of data leaks and ensures sensitive information remains secure.
What is RAG?
Retrieval-augmented generation (RAG) is an AI framework and powerful approach in NLP (Natural Language Processing) where generative AI models are enhanced with additional knowledge sources and retrieval-based mechanisms. These supplementary pieces of information provide the model with accurate, up-to-date data that complements the LLM’s existing internal knowledge.
As the name suggests, RAG models have two main components:
- Retrieval Component: Fetches relevant information from a knowledge base, such as data stored as vector embeddings in a vector database.
- Generation Component: Creates a response based on the retrieved information.
By combining these two processes, RAG models enhance the quality of LLM-generated responses, offering more accurate, contextually relevant, and informative answers.
In this primer, we will discuss the origins of RAG, how it works, its benefits, and ideal use cases. We'll also provide a step-by-step guide on how to implement RAG for your models and deploy RAG-powered AI applications.
Fun Fact About the Name "RAG"
The term RAG was coined by Patrick Lewis and his research team in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Lewis has joked that had he and his research team known the acronym would become so widespread, they would have put more thought into the name.
Origins of RAG
To understand the origins of Retrieval-Augmented Generation (RAG), it's helpful to look at the larger field of question-answering systems, which are designed to automatically answer natural language questions.
The history of question-answering systems dates back to the 1960s and the early days of computing. Notable early examples include SHRDLU, which could interact with users about a small, predefined world of objects, and Baseball, a program that answered natural language questions about baseball game data. These early systems primarily focused on locating and returning relevant documents or data.
In the '90s, the advent of the Internet brought new developments. Ask Jeeves, which provided a natural language question-answering experience, is one example. While it aimed to answer questions with relevant information from the Internet, search engines like Google eventually took the lead due to superior algorithms and technologies for indexing and ranking web pages. This ability to identify the most relevant information remains crucial today.
The 2010s saw significant advancements with systems like IBM's Watson, which gained fame for outsmarting Jeopardy champions Ken Jennings and Brad Rutter. Watson, trained on over 200 million documents, demonstrated the ability to understand and accurately answer natural language questions. This milestone in question-answering systems paved the way for the next generation of generative models.
As neural models for natural language processing continued to evolve, new solutions to previous limitations of retrieval systems emerged. For instance, RAG streamlines operations by reducing the need for continuous retraining, making it efficient for enterprise use. However, while LLMs might not need retraining, the retrieval component of the RAG pipeline may require updates for new datasets or different application areas. For example, a finance-focused LLM would need a specialized retrieval model to achieve comparable results in the medical domain.
By understanding these origins and developments, we can better appreciate the innovation that RAG brings to the field of AI and question-answering systems.
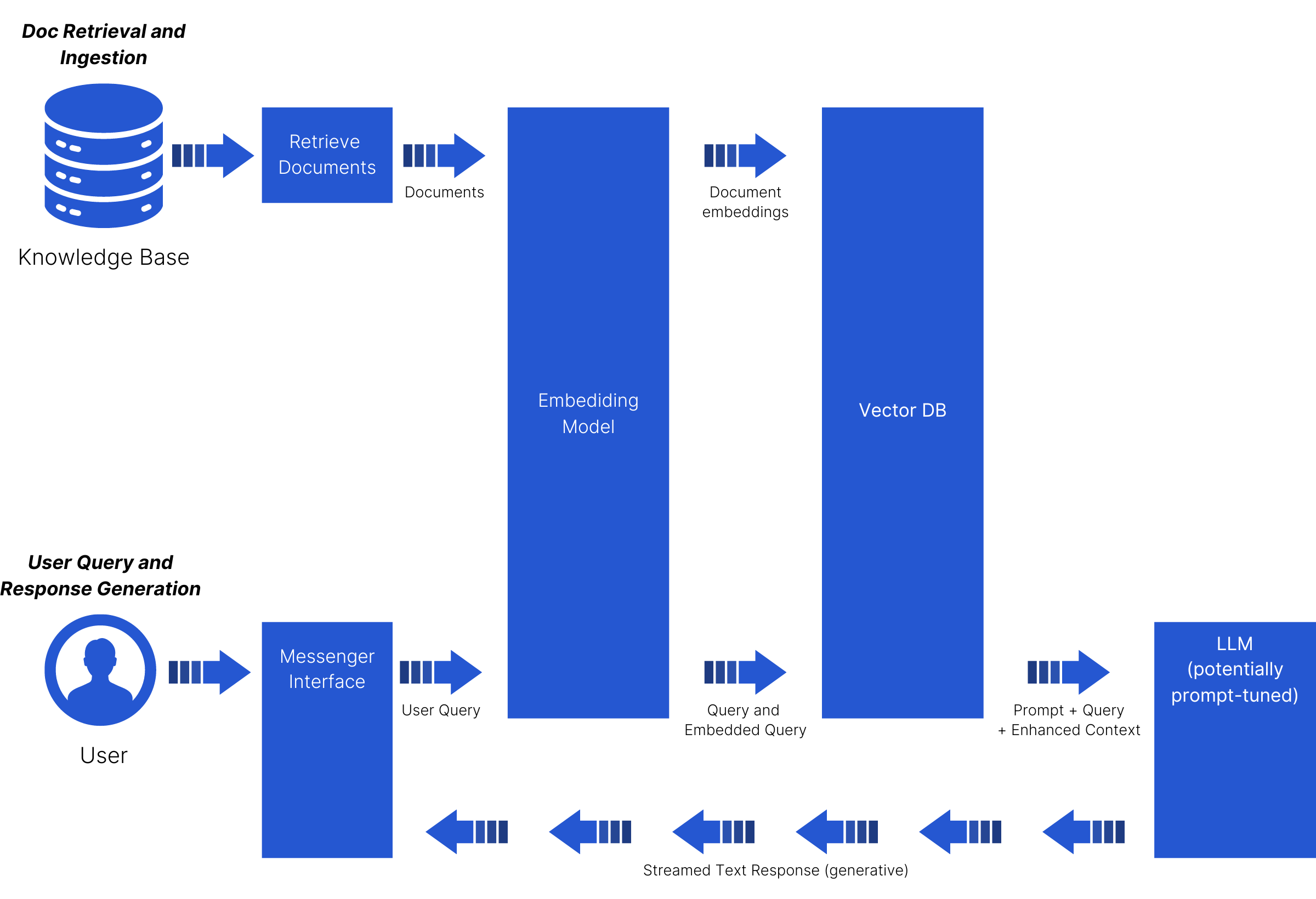
How RAG Works: A Five-Step Process
1. Question/Input: The user poses a question.
2. Retrieval: RAG searches a vast database for relevant information.
3. Augmentation: It combines and processes the retrieved data.
4. Generation: It crafts a detailed, engaging response.
5. Response/Output: The final answer is presented to the user.
Retrieval-Augmented Generation (RAG) Sequence Diagram
Why RAG is a Big Deal in AI
RAG enhances interactions between humans and machines by providing accurate, contextually relevant answers. This makes conversations with AI feel more natural and informative, enabling AI to cover a broader range of topics in depth.
Schema of RAG
| Component | Function |
|---|---|
| Pre-trained LLM | Generates text, images, audio, and video. |
| Vector Search | Finds relevant information based on vector embeddings. |
| Vector Embeddings | Represents the semantic meaning of data in a machine-readable format. |
| Generation | Combines LLM output with retrieved data to generate the final response. |
Who is Using RAG?
RAG is a major improvement to modern question-answering systems. Any role or industry that relies on answering questions, performing research and analysis, and sharing information will benefit from models that leverage RAG. Here are just a few example scenarios:
| Use Case | Description |
|---|---|
| Conversational Chatbots | Enhances customer service by providing accurate and up-to-date answers from a company's knowledge base. |
| Personalized Recommendation Systems | Offers tailored and up-to-date suggestions to users based on their preferences, behaviors, and contextual information. |
| Legal Research | Provides access to up-to-date case laws and regulations, streamlining research processes for legal professionals. |
| Financial Analysis | Improves efficiency in analyzing real-time market data for financial analysts. |
Orchestrating RAG Processes
Combining various RAG operations into automated solutions involves:
| Process | Description |
|---|---|
| Question Answering | Extracts relevant details for a query. |
| Information Retrieval | Scours a corpus for relevant data. |
| Document Classification | Categorizes a document using the fetched context. |
| Information Summarization | Generates a summary from identified details. |
| Text Completion | Completes text using the extracted context. |
Assembling RAG Flows: From Basic Building Blocks to Valuable Use Cases
Steps of assembling RAG Flows
Step 1: Identify the business challenge or objective
Step 2: Identify and select the right data sources
Step 3: Configure and fine-tune the retrieval mechanism
Step 4: Optimize the generation model to ensure effective processing and presentation of data
Step 5: Gather user feedback for continuous improvement
Step 6: Adapt and refine the RAG configurations
Case Study: Request for Proposal Processing with RAG
Steps in RFP Processing Setup
Step 1: Users upload RFP files and supplementary documents
Step 2: Users can preview the RFP and pose queries
Step 3: RAG offers insightful recommendations to enhance the likelihood of winning the bid
Step 4: Users can activate the feature to generate responses to the RFP
Step 5: Users preview the generated responses and modify them if necessary
Step 6: Users can provide feedback to refine the answers
Step 7: The finalized RFP is exported, ready for submission
How Does RAG Work?
RAG has some core building blocks: a pre-trained LLM (responsible for generating text, images, audio, and video), vector search (retrieval system responsible for finding relevant information), vector embeddings (essentially numerical representations of semantic or underlying meaning in natural language data), and generation (combines the output of the LLM with information from the retrieval system to generate the final output).
Summarization: The Benefits of Using RAG
Adding RAG to an LLM-based question-answering system has five key benefits:
| Benefit | Description |
|---|---|
| Accurate Information | Provides the most current and reliable facts. |
| Builds Trust | Offers source verification, enhancing accuracy and trustworthiness. |
| Time and Cost Optimization | Reduces the need for continuous retraining, saving time and financial resources. |
| Customization | Allows for personalized responses, tailoring the model to specific needs by adding knowledge sources. |
| Full control over data | The knowledge base augments the LLM, eliminating reliance on pre-trained information. |
Conclusion
Retrieval-Augmented Generation (RAG) marks a significant leap forward in the field of artificial intelligence. By integrating external knowledge, RAG empowers large language models (LLMs) to deliver more accurate, reliable, and personalized responses. As this technology continues to advance, it promises to evolve our interactions with AI, making these systems more efficient and trustworthy than ever before.
RAG is just one of the many emerging methods aimed at expanding an LLM's knowledge base and decision-making capabilities. It adopts an open-book approach, enabling LLMs to tackle questions that were previously challenging to answer accurately.
While there is speculation that extended context windows could make RAG obsolete, experts like David Myriel argue that such solutions demand significantly more computational resources and processing time. For now, RAG remains a powerful tool for enhancing the quality of responses generated by LLMs.
Ready to elevate your AI capabilities? Discover the potential of RAG-powered applications today. Enhance the accuracy and relevance of your AI content, and unlock new possibilities for personalized, context-aware solutions across various industries. Visit our website to learn how our FAQ module can integrate a database of Frequently Asked Questions into your preferred messenger interface, transforming your user experience.
Find out more now!References and Additional Information
For further reading on RAG, refer to these sources:
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Patrick Lewis et al., 2020, Available here
- RAG 101: Demystifying Retrieval-Augmented Generation Pipelines by NVIDIA, Available here
- What is Retrieval-Augmented Generation? by NVIDIA, Available here
- Retrieval-Augmented Generation: Grounding AI Responses in Factual Data by Minh Hoque
- The Future of Retrieval-Augmented Generation: A Journey from Concept to Hyper-Customization (2024) by R. Lavigne
- What is RAG (Retrieval-Augmented Generation)? by Clarifai
- Retrieval-Augmented Generation and LLMs by Grid Dynamics
- Retrieval-Augmented Generation by Oracle, Available here
- Is RAG Dead? The Role of Vector Databases in Vector Search by Qdrant, Available here
Check this video to find out more